ToyDB : B+Tree Index
ToyDB 의 인덱스 구조 중 하나인 B+Tree 구조를 완성했다. 지난 포스팅에서 “다만, 생각보다 순조롭지는 않았다.” 라고 했던만큼, 엄청 막힘없이 진행되지는 않았다. 소스코드는 여기에 있으니 혹시 궁금하신 분들은 들어가보시길. 또한 프로젝트에 대한 조언은 언제나 환영한다.
Index Management
이전에 구현한 File System과 Buffer System만으로는 사실 DBMS라고 볼 수는 없다. 단순히 파일을 열고, 읽고, 쓰고, 닫고만 가능한 프로그램인 것이다. 물론 그것만으로도 데이터를 찾고, 추가하고 등의 작업은 가능하다. 단순히 전체 파일을 읽으면서 데이터를 찾고, 데이터 추가는 그냥 파일 맨 끝에 하면 그만이기 때문이다. 그러나 이런 방식은 DB 파일이 조금만 커져도 상당히 느릴 수밖에 없다. 따라서, 데이터를 빠르게 찾거나 추가하기 위해서는 이 데이터를 잘 정리해서 나중에 탐색하기 편하게 해야 한다. 이를 인덱스라고 하며, 실제로는 B+Tree, Hash Table, Radix Tree, Skip List 등등 다양한 구조가 사용된다.
기존 학부 과제에서 B+Tree 구조를 사용했기에, 이를 우선적으로 구현하기로 했다. 본래 C로 구현한 적이 있기 때문에, 비교적 구현의 난이도는 그리 높지 않았다. 다만, 기존 코드를 최대한 참고하지 않고, 내 기본 지식으로 구현하려 하다 보니, 자잘한 실수가 좀 많았다. (예를 들자면…, Node Split이나 Merge 등의 이유로 부모가 바뀌었는데 이를 자식들에게는 반영하지 않아서 나중에 꼬인다던지…,key와 page_no를 서로 바꿔서 쓴다던가…) 덕분에 디버깅을 2~3시간 정도 했다.
B+Tree Implementation
이 글이 B+Tree에 대한 정리나, 강의자료가 아니기 때문에, B+Tree의 로직을 설명하지는 않을 것이다. 찾아보고 싶다면, 여기에서 간략한 설명을 보거나, 직접 구글링을 해서 찾는 편이 더 좋을 것이다. 컴공이라면 아마 2~3학년에 꼭 배울 자료구조이기에, 미리 찾아두어도 나쁘지 않으리라 생각한다. 아무튼, 자세한 설명을 생략하더라도 딱 하나, Delayed Merge에 대해서는 설명하고 넘어가겠다.
본래 B+Tree는 한 노드가 포함한 Key의 개수가 Order(각 노드가 가질 수 있는 Key의 최대 개수)의 절반 아래로 내려갈 경우 Merge/Redistribute가 발생한다. 그 중 merge는 아래와 같은 식으로 발생한다. 아래의 예시는 Order가 4이다.
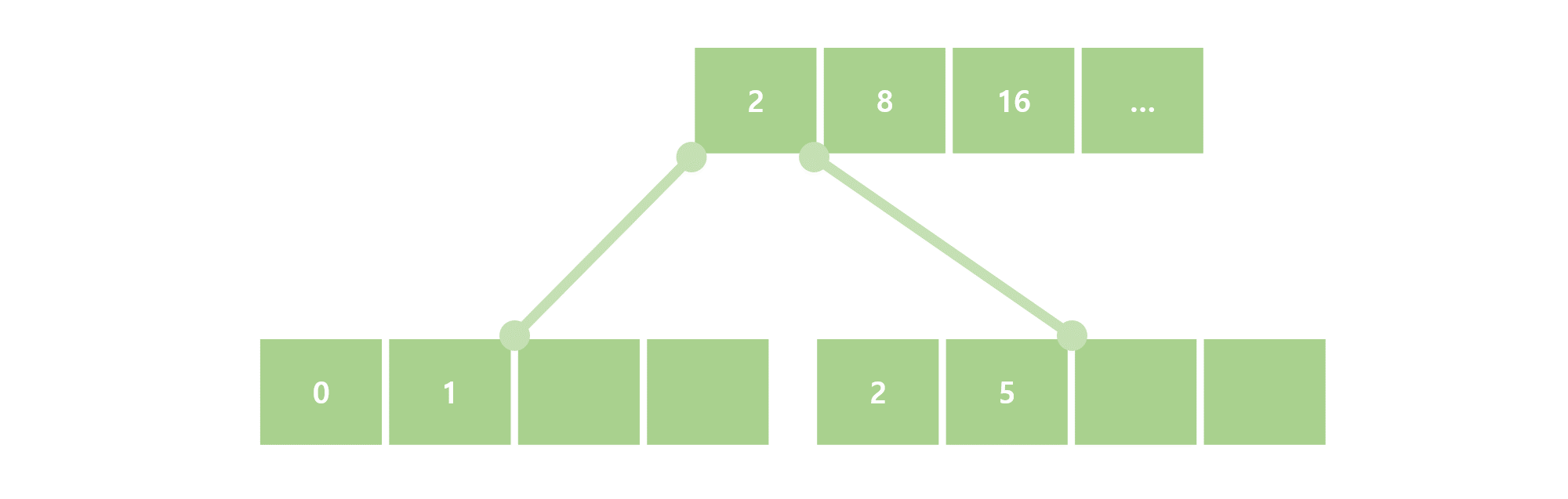 여기서 5를 지우게 되면 남은 Key가 하나가 되는데, 따라서 이웃 노드에 여유분의 Key가 있는지 봐야 한다. 그러나 이웃노드에도 딱 2개의 Key가 있는 상황이므로, 이럴 때는 결국 두 노드를 합쳐서 바로 아래의 이미지와 같아진다.
여기서 5를 지우게 되면 남은 Key가 하나가 되는데, 따라서 이웃 노드에 여유분의 Key가 있는지 봐야 한다. 그러나 이웃노드에도 딱 2개의 Key가 있는 상황이므로, 이럴 때는 결국 두 노드를 합쳐서 바로 아래의 이미지와 같아진다.
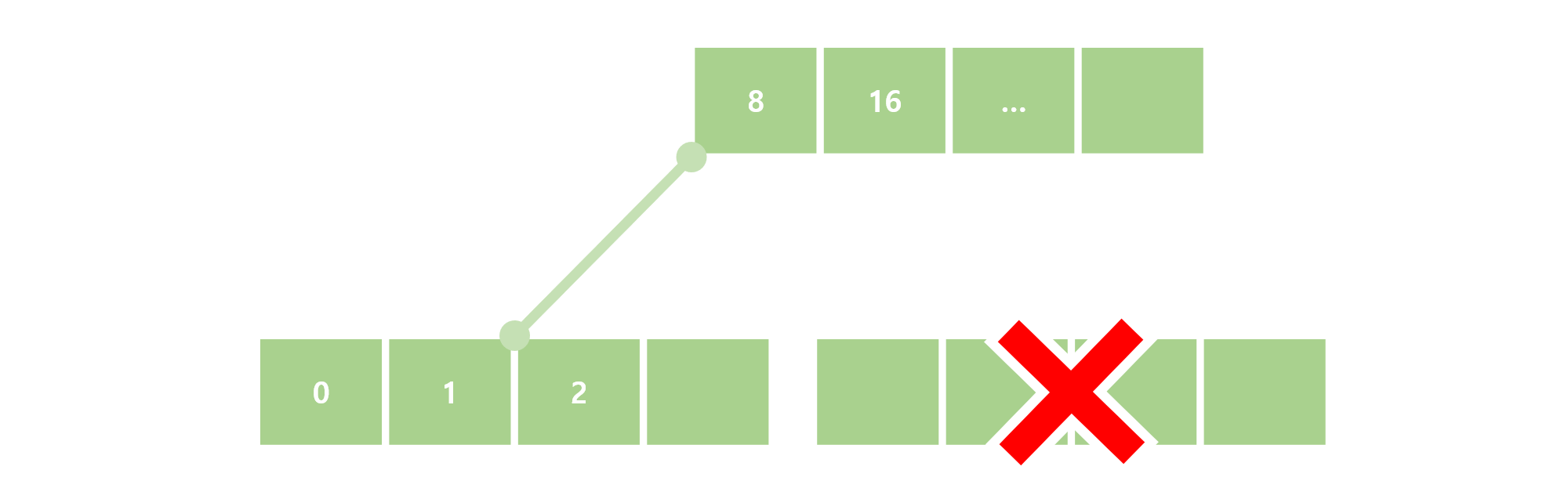 그런데 이 상황을 보면 다시 2개의 Key가 Merge된 노드에 들어갈 경우 다시 split이 일어나게 되고, 그럼 또 Key 2개, 3개의 노드 2개로 나뉘게 되는데, 이 노드들은 2번의 delete 연산으로 다시 Merge될 수 있다. 절반 아래일 때 Merge를 수행하는 것은 특정 상황에서는 Merge와 Split을 반복시켜서 DB의 성능을 크게 저하시킬 수 있는 것이다.(이는 Merge와 Split이 단순히 한번으로 끝나는 연산이 아닌, Root까지 영향을 미치는 큰 연산이기에 그렇다.) 따라서 이러한 상황을 피하게 하기 위해 Merge의 조건을 아예 그 노드에 Key가 없어질 때로 늦추는 것이 Delayed Merge이다. 실질적으로는 Merge가 아닌, 단순히 페이지를 버리는 연산이지만 말이다.(애초에 합칠 Key가 없으니, Merge라고 하는 것이 이상하긴 하다.) 아무튼, 이러한 로직을 Delete 연산에 포함해서 B+Tree Index를 구현했다.
그런데 이 상황을 보면 다시 2개의 Key가 Merge된 노드에 들어갈 경우 다시 split이 일어나게 되고, 그럼 또 Key 2개, 3개의 노드 2개로 나뉘게 되는데, 이 노드들은 2번의 delete 연산으로 다시 Merge될 수 있다. 절반 아래일 때 Merge를 수행하는 것은 특정 상황에서는 Merge와 Split을 반복시켜서 DB의 성능을 크게 저하시킬 수 있는 것이다.(이는 Merge와 Split이 단순히 한번으로 끝나는 연산이 아닌, Root까지 영향을 미치는 큰 연산이기에 그렇다.) 따라서 이러한 상황을 피하게 하기 위해 Merge의 조건을 아예 그 노드에 Key가 없어질 때로 늦추는 것이 Delayed Merge이다. 실질적으로는 Merge가 아닌, 단순히 페이지를 버리는 연산이지만 말이다.(애초에 합칠 Key가 없으니, Merge라고 하는 것이 이상하긴 하다.) 아무튼, 이러한 로직을 Delete 연산에 포함해서 B+Tree Index를 구현했다.
2019년에는 주석 포함 900줄 가량으로 구현을 했었는데, 이번에는 주석을 제외하고 600줄만에 B+Tree를 구현할 수 있었다. 사실 2019년 코드도 주석을 다 제거하면 한 6~700줄 정도일 테니, 코드를 컴팩트하게 짜는 능력이 그리 크게 늘었다고 보기는 힘들다. 하지만, 기존에는 2~3주 걸렸던 구현을 단 6일만에 해낸 것은 나름대로의 성장이라고 볼 수 있을 것 같다.
Next Step
- Next Index : Skip List
이제 Skip List를 구현할 차례이다. 여기에 Skip List 구조 자체는 구현해본 적이 있으니, 구현 자체에 애를 먹지는 않을 것 같다. 다만, 노드 구조를 4kb에 맞추고, 기존의 B+Tree 기반 API를 Skip List에도 대응할 수 있도록 추가하는데에 어느정도 고민이 필요할 듯하다. - Next Next(?) Index : Radix Tree
논문에서도 상당히 많이 언급된 Radix Tree, 흔히 Trie라고 부르는 구조를 Index로 구현해볼 생각이다. 이것도 여기에 구현은 해봤으니 큰 어려움은 없겠지만… 역시 노드 구조나 API 변형이 조금 걱정이다.